Some time ago, in the early days of Android development, the testing strategy was often the great forgotten in the projects for this platform.
I think there were a few fundamental reasons for this. For a start, we didn’t have clear design or architecture patterns to follow that facilitate the task of implementing testable code, this is code separated by responsibilities and isolated from implementation details and the Android Framework. Nowadays this is not so common but as we know we are all guilty at some point of our career as Android developer of placing all data, business and view logic in the same place, usually a big bloated Activity making the testing of this functionality pretty much impossible.
On the other hand, the Android SDK wasn’t facilitating this task as we didn’t have good testing framework and libraries, aside from basic JUnit tests and some automation features. It was difficult to set up and run, the primitive IDE didn’t help either (remember Eclipse?), documentation almost didn’t exist and Google itself didn’t provide proper guidelines and examples on this matter.
On top of that, maybe what I consider even the worst of the problems, we developers quite often didn’t consider a good testing strategy as a first class citizen but instead, more as overhead and an amount of work and time we couldn’t afford to spend (this still happen in some cases now days, but that is a different story for a different post).
Thankfully this now days has changed and most teams have in place some kind of testing approach. The Android framework has evolved a lot and it provides an extensive set of tools and a good framework for a different type of tests. The Android community has embraced several types of architecture and design patterns that facilitates the tests implementation for the different layers and components of the applications and we developers are more conscious about the critical role of a good test approach.
But despite all these improvements I believe that quite often we still struggle to implement an effective automated test strategy, able to guarantee as much as possible the correctness of all the different functionalities of our apps with a good return of investment from our time and effort.
What should I unit test and which is the scope of them? Do I need UI tests and how can I make them as fast and reliable as possible? What about integration tests, do I need them and what for? What about end to end tests or manual quality assurance? Should I favour any kind of tests over the others?
The purpose of this first article is to propose and describe an approach which I consider is an effective testing strategy that maximise the time and effort we spend providing the best return in terms of correctness, quality assurance and stability of our products. I will describe what I believe is the best way to distribute and use the different type of tests and tools we have in Android. In following posts I will be extending the information about different particular topics when they need a more in deep description and level of detail.
Why do I need a good testing strategy?
The main goals when we implement our test strategy are:
- Allow the organic and sustainable growth of the code base maintaining the quality, robustness and stability.
- Avoid slowing down and stalling of the development work.
- Facilitate the ability to continuously improve, change and expand the functionalities of the product.
So we can’t deny the benefits of well rounded testing implementation, but to achieve this sweet spot we need to design carefully how are we going to invest our precious time. Tests implementation and running can be expensive and time consuming, and in many cases we might fall in the trap of creating test cases for the sake of tick the coverage boxes without getting any real value from them.
Requisites for a solid testing strategy
So what are the requirements to consider our approach effective and solid?
- Priority to the important and critical parts of the code. The domain layer, classes and components that implements business logic, algorithms, etc. In here is where we need to put all our attention and efforts. This is the code that provides more value so it’s the code we need to protect the most with a good test safety net. Outside this area, we have mostly external services, database, network, infrastructure, etc.
- Integrated in the development cycle. Test suites must be integrated in the workflow of the development team, they have to be part of the Continuous Integration flow and run every time we intend to merge new changes.
- Reasonable development and maintenance cost with a good return of investment ratio. This means that our tests must provide high value and a good safety net but without penalising excessively the time and efforts to implement, run and maintain that make the task of implement this tests not worth it for the returned value.
In order to achieve this sweet spot of the highest value at lowest cost possible, we need to design carefully the test strategy: What type of test are the most adequate for this class, component or feature? Should I use Unit or Integration Test? Shall I follow strictly the usually recommended test pyramid?
We might think that a straightforward solution would be implement mostly UI tests using Espresso. At the end of the day we are a front end system and we are interested in testing that what the user see and the visual experience is correct and everything work as expected. If I can test that a whole user flow is working properly by emulating the same behaviour and checking the result, we can consider that the implementation is correct and defect free.
But UI tests are expensive to implement and slow to run. In some cases we need to set up complex application state that might include login, accessing remote and local data, maybe even access to device capabilities like camera, Bluetooth, etc. Or we have to go through a long user flow, and things get even worse when if the application has a considerable size and we have tons of screens and flow. If we need to run a whole tests suit of this type in a big application after every commit in the main branch, as we should, development cycles can get extremely long and cause a bottleneck in our Continuous Integration pipeline and in the general development flow.
In some projects things can get even worse when on top of the UI tests, and because we didn’t managed to create a good safety net and confidence in the quality achieved by our automated tests, we decide to also have in place and run a lot of manual tests. We end up with one of the common anti patterns in testing strategy, the testing cupcake, as described in this article by ThoughtWorks. On top of long UI automated test sessions we have to perform long cycles of manual tests.
To avoid these issues let’s take a look to a more heterogeneous approach that can help to keep test suites faster to run and less costly to maintain and develop while keeping a high level of confident in the correctness of the code.
The Strategy
The first requisite to be able to implement our strategy is that the application must be designed with an architecture that facilitate separation of concerns and modular design. Clean Architecture is a good example that is widely adopted in the Android community, but any other pattern would be perfectly valid. Apart from the obvious benefits of having in place a good architecture, like scalability, flexibility, adaptability, and so on, a well designed code base will make possible the testability of classes of modules with minimum friction and effort. A class that contains too many dependencies, with some of them belonging to the Android framework or other third party component will make the testing process really difficult if not impossible in many cases.
In order to guarantee the correctness of a feature as much as possible in the most effective and cost efficient way, we will be using a variety of type of test at a different levels of the code structure to maximise coverage. For this we are going to implement a combination of Unit, Integration, End to End, UI and Manual tests.
We need to prioritise automated over manual tests. Manual tests take long time to run, are prone to human error and more expensive in resources. We can launch the suite of automated tests for the whole project as many times as we want, but we can’t ask a human to test again and again the whole system every time we need it.
Having the majority of tests automated means we need to be able to run them as fast as possible. If we can guarantee and maximise the correctness validation of our application quick and automatically, this is going to allow us to develop, deploy and release much faster and frequently making our agile and train release process a well greased and efficient machine.
And this is what makes so important to choose a good combination of tests. If most of our tests are UI based end to end tests, running the whole test suite is going to be painfully slow and in many cases a flakey process. We need to provide the same level of confidence of correctness with faster and reliable combination of tests.
So to summarise all this, and because the reader quite probably will be familiar with the classic test pyramid defined by Mike Cohn, below we can see a variation of that as a graphical representation of all this strategy defined so far:

So now let’s take a look now at a high level the different type of tests that we need to implement and the purpose of each one. In the next blog posts we will dig into more detail about all of them, tools and libraries to use, examples and recommendations.
Unit Tests
These should be implemented in critical parts of the code base, usually domain classes containing business rules, algorithms, etc.
What is an Unit Test and how to approach the implementation and the different techniques will be the topic of the part II of this series of articles. The There is a lot of debate and different philosophies to approach unit tests implementation, but to summarise the key concepts, they must be focused in a single unit of behaviour, not necessarily a single class and we should try to use real dependencies as much as possible, trying to minimise the use of mocks and fakes to only when really necessary. Is also important that we test what this component does, but not how they do it.
Integration Tests
These are test where we are going to validate that different components of our system are working together correctly. For example we could be testing how a repository, an Interactor and a ViewModel are working together and if based on a data state in the repository the view model is receiving the expected data in the correct type and format after a request via the Interactor. These tests run in the JVM and not in a emulator or a real device, making them fast and reliable.
Once again here we can see how important is to implement a good architecture in our application, so we can define the different responsibilities and scope of the tests. Something to take into account here is that in some cases we will might be unit testing one class or component and also we will be testing how this component work together with other components to achieve certain task.
As we can see in the pyramid, is in these type of tests where we should spending much of our time because is where we are going to receive more value for this investment. These tests are fast to execute as they don’t depend on a mobile phone or emulator.
UI Tests
In here what we are going to test is that the screen is representing a state of the app correctly, with the right data, position of the component, user interactions, etc. These run in a real device or an emulator, which mean they are expensive and slow. If we are using the MVVM pattern, the way to go is just to define and set up states and the models with different data depending on the test scenario and validate the UI with the Espresso assertions. The key here is that we are just testing the UI in isolation of the rest of the application, this tests should be relatively fast to run. As we will see in next articles here the Android class FragmentScenario is our friend.
End to End Tests
These are the most expensive to implement and slow to run of all the tes types, for this reason we will be implementing as fewer as possible, prioritising those critical user flows and core functionalities of our app. These are blackbox tests so we are testing the scenarios in the same way a user would be using the application. This provides a strong assertion about the correctness of the features in our app as we are testing the whole implementation, and if we have staging or other kind of development environment we can actually be including the network requests and any other external process.
Manual Tests
Finally we have the tests performed by humans. If we have implemented a full suite of tests off all types described above, these should be the smaller section of all the process. In here the QA team (if we have one, if not the developers) should be just running some smoke tests and any edge cases that couldn’t be asserted with all the automated tests implemented so far. Basically we should avoid to test again anything that has been already tested by the automated suites. And this apply to any other kind of tests implemented before.
Designing the tests suite
So based in all the concepts and theory described above, how do we select what type of test apply to the different components of the app? What should be the scope of the integration tests? Let’s see with a practical example what could be an effective design.
Below we can see a classic Clean Architecture approach to implement a common use case in an application, this is we fetch some data from a remote or local data source and then display on the screen some kind of information based on this data.

So, let’s start with the Unit Tests. As mentioned before we want to test the unit of behaviour of a specific component. In this example as we can see in the diagram below, we want to test the Use Case (also known as Interactor) and the Repository. These components might contains logic that we need to test. In the case of the Repository it could be the logic to select between source of data, or some data model transformation, etc. Same thing with the use case, we might have some business logic or any other domain operation that needs to be tested.
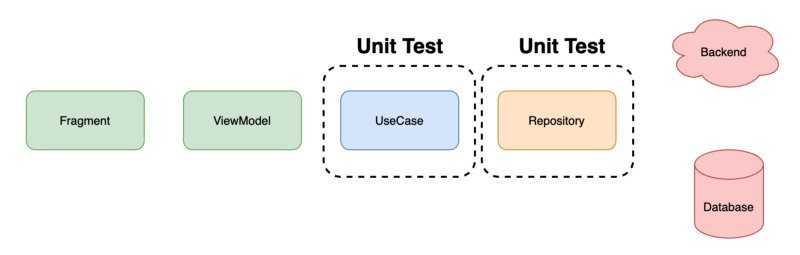
Now that we have implemented the unit tests for the Use Case and the Repository and we can confirm the correct behaviour and correctness the functionality that they provide individually, is time to validate how these components work together. For this purpose we start with the Integration Test. The idea is to make them as bigger in scope as possible including as many components involved in a feature or data flow as possible. For our example we decide that we are going to test from the repository up to the ViewModel. So providing a fake version of the data that the repository fetch from the backend or database, we will assert that the ViewModel is creating the right states, view data models, etc. This way we are testing all the contracts of all classes involved, the mapping to different models to cross boundaries, the exception management, etc, etc.
In important to note that we are leaving out of the test the components that we don’t control, the out of process elements like the backend and database. We want to run this tests in the JVM and do not depend on a emulator or real device. We want to avoid brittle and flaky tests, and if we depend on a real database or a backend that is going to be almost impossible. If the network fails the test will result in a false negative. If we need to populate the database or wait for a request in a real device, they will be slow and difficult to set up. Below we can see a diagram representing this approach.

Now is turn for the UI test, which are the only ones we want to run in an emulator of real device. For this reason we want to make then small and focused on pure UI assertions. So as represented in the diagram, we are going to inject in our ViewModel the data models that represent a state of the application. We will be using FragmentScenario to launch in isolation that screen and then using Espresso we will assert that the view is actually representing the state defined by the ViewModel. We will be checking that we are displaying the right components with the right copies, is any of them must be visible or not, enabled or not, the events dispatched by the View to the View Model, etc. As we can see here there is no full users journeys and full features tests, just pure UI testing of a single view.

And finally is time for the End to End test where again we are going to use real devices or emulators but in this cases we will be launching the whole app and performing complete users flows and feature testing as described in the diagram below.

Summary
So this is it. In this first part about implementing a good test strategy for our Android projects I have tried to define and explain an approach that I considered balanced and effective. The main goal is to maximise the time and dedication spent in testing while getting the most return of investment and minimising the human testing efforts.
In the following articles we will focus on the details of the different type of tests, recommendations, best practices and implementation details for a good automated test.
I would love to hear your feedback, ideas or different approach about this topic and the content of the article. Please feel free to drop any comments and thanks for reading!
 From a user point of view there is also this relaxed perception about the security of our devices. As we are going to see in this post we should take much more seriously the security of our platform, as developers and also as users, taking into account the massive amount of personal information that we carry in our devices. And here we as developers have a big responsibility.
From a user point of view there is also this relaxed perception about the security of our devices. As we are going to see in this post we should take much more seriously the security of our platform, as developers and also as users, taking into account the massive amount of personal information that we carry in our devices. And here we as developers have a big responsibility.





 where we have allocated the Android project.
where we have allocated the Android project. On the other hand MadridBus wasn’t so popular, probably because there were already a few decent applications in the market for the city of Madrid, so we didn’t focus so much on it. As a result, now days the app looks and feel really outdated, the UI is clunky and the plumbing of the app are really ugly and not maintainable.
On the other hand MadridBus wasn’t so popular, probably because there were already a few decent applications in the market for the city of Madrid, so we didn’t focus so much on it. As a result, now days the app looks and feel really outdated, the UI is clunky and the plumbing of the app are really ugly and not maintainable.

 60-70% of our test code base and the rest 30% should be implemented as End-to-End tests (Integration, functional, UI tests).
60-70% of our test code base and the rest 30% should be implemented as End-to-End tests (Integration, functional, UI tests).